
Eve Dev Diary (Jul - Sep)
Jamie Brandon - 15 Oct 2015
Whoops, it’s October already. Time flies when you’re having fun.
We released all of our work under the Apache 2.0 License. A ton of work went into the inevitable cross-platform woes - much thanks to everyone that reported bugs and contributed fixes.
With the release came an array of basic features that we had neglected so far, including saving/loading Eve programs and importing csv files.
The AST and compiler have been significantly cleaned up. The new compiler is written using a crude pseudo-Eve as a step towards true bootstrapping. To better support live programming, the compiler can now handle broken or unfinished programs without losing runtime state - freezing any broken views while continuing to run any undamaged views.
The language itself received some new features. Ordered union and difference allow easily expressing non-monotonic logic such as “all birds can fly, except penguins can’t, except Harry the Rocket Penguin can”. The addition of grouping operations and first-class bags has allowed aggregates to treated as normal primitives. Existing primitives have been extended to handle coercion between numeric and string types (hopefully a temporary measure, to stave off the inevitable type system).
Error handling appeared too, or more accurately error ignoring. Reporting errors in a declarative query language is tricky because the programmer does not control the order of operations. Whether an error like division by zero actually occurs can depend on whether the query planner schedules the division earlier or later in the query. The zero in question might be filtered out by another constraint before the query finishes. Currently we treat primitive functions as true relations, so division by zero simply returns no rows, but we report such events in a separate table which can be queried for self-monitoring.
Entering and editing data in a live relational program is surprisingly hard. Myriad corner cases challenge the UX, such as edits that cause the sort position of the edited row to change. The new editor handles these much more smoothly than the old Excel-lookalike.
The default interface for queries is currently a drag-and-drop graph editor.
The preview box helps explore partial results within the query, to aid debugging.
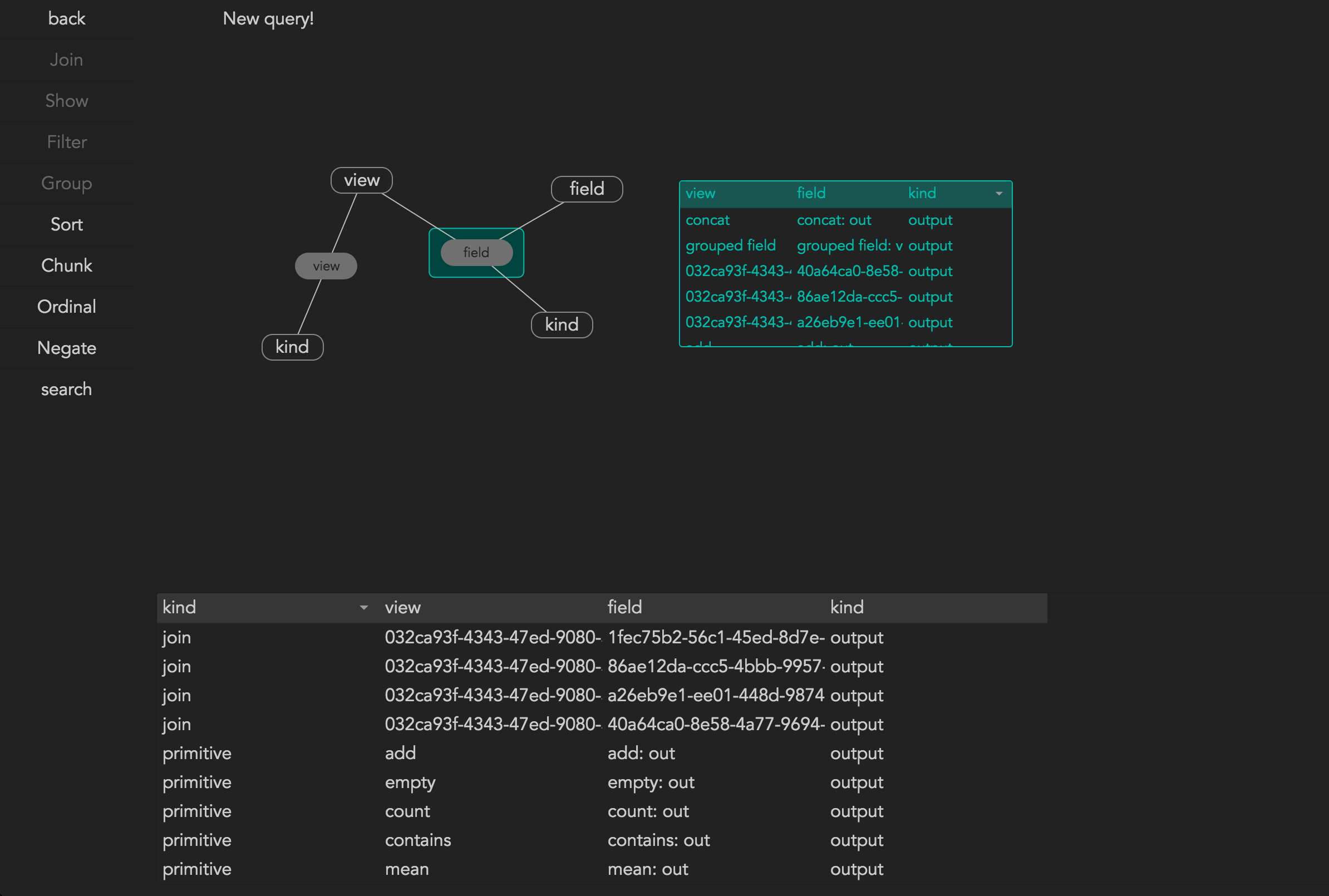
This interface is quickly grasped by everyone (with the exception of the grouping/sorting operation which is currently something of a dumping ground for everything that doesn’t fit neatly into relational algebra) but the information density is very low and laying out graphs is a legendarily underappreciated problem.
We are also revisiting the old madlib ideas which allow fitting much more code onto the screen at once.
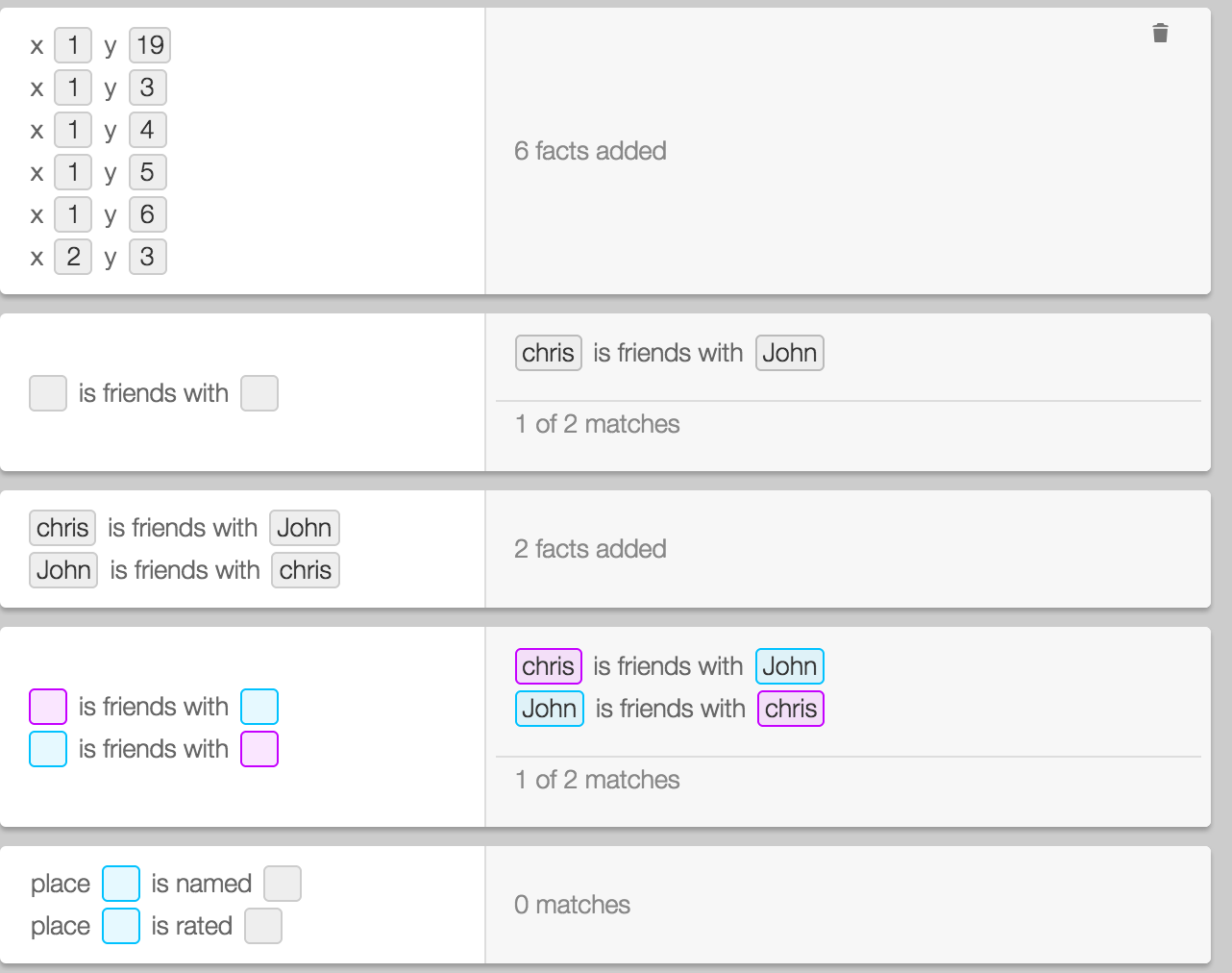

This interface works particularly well on mobile, especially when voice entry is enabled.
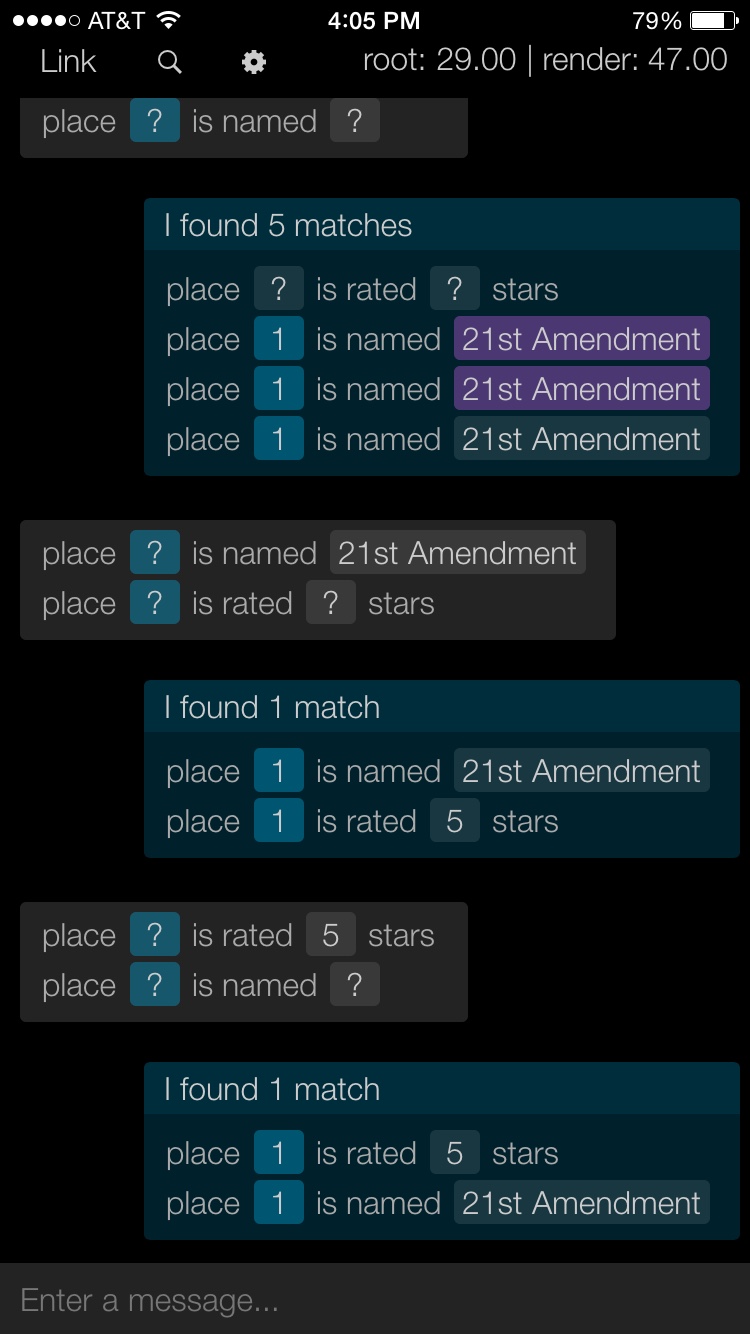
We have several more experiments in progress. More on those in the next post…